Tadalafil appartiene alla classe degli inibitori selettivi della fosfodiesterasi di tipo 5, con un profilo farmacocinetico caratterizzato da un’emivita terminale di circa diciotto ore. Dopo somministrazione orale viene assorbito rapidamente e raggiunge concentrazioni plasmatiche massime in due ore. La biotrasformazione avviene principalmente tramite CYP3A4 con formazione di metaboliti inattivi, escreti in prevalenza con le feci. L’elevato legame alle proteine plasmatiche (>90%) assicura una distribuzione stabile. Nei confronti delle altre molecole della stessa classe, cialis compresse italia è noto per la durata prolungata dell’attività farmacologica.
Download2.polytechnic.edu.na
Extraction of Adverse Drug Effects from Medical Case Reports
Harsha Gurulingappa1 , Abdul-Mateen Rajput 2, and Luca Toldo 2∗
1Molecular Connections Pvt. Ltd., Basavanagudi, Bangalore 560004, India
2Merck KGaA, Frankfurterstraße 250, Darmstadt 64293, Germany
ABSTRACT
adverse drug reactions for automated signal generation in pharma-
A sheer amount of information about adverse effects of drugs are
covigilance has already been proposed (Henegar et al., 2006) and
published in medical case reports that pose major challenges for drug
its application to information retrieval has been exploited by the
safety experts to perform timely monitoring. Efficient strategies for
same group few years later, in the VIGITERMES project (Dela-
identification and extraction of information about adverse drug effects
marre et al., 2010), where the OntoEIM adverse event ontology
from free-text resources are needed to support pharmacovigilance
have been used to extend the dictionary of adverse event entities,
research and decision making. Therefore, this work focusses on the
normalize queries, and consolidate annotations, delivering 29% pre-
adaptation of a machine learning-based relation extraction system for
cision and 67% recall of MEDLINE abstracts. Automatic extraction
the identification and extraction of drug-related adverse effects from
of adverse drug effects from clinical records is an active area of rese-
MEDLINE case reports. It relies on a high quality corpus that was
arch (Aramaki et al., 2010). Mining social internet message boards
manually annotated, using ontology-driven methodology. Qualitative
to identify adverse drug reactions has been reported (Benton et al.,
evaluation of the system show robust results.
2011), whereby in that work the extraction of event - drug pairs wasdetermined only using co-occurrence of terms within a window of
INTRODUCTION
20 tokens apart, and the use of machine learning systems was only
Adverse effects of drugs is a bothersome issue that confronts drug
focused on deidentification for privacy protection. This work reports
manufacturers, healthcare providers, and regulatory authorities.
on the adaptation of a machine learning-based system for identifying
Stringent measures for capturing the risks associated with drug
the relations between drugs and adverse effects in MEDLINE case
usage are established in forms of spontaneous reporting systems that
reports, that relies on an ontology-driven manually annotated cor-
are timely analyzed to ensure safe use of drugs (Hauben and Bate,
pus, that strictly follows semantic annotation guidelines developed
2009). Amongst various data sources used by drug safety experts to
for clinical text (Roberts et al., 2009). The system has been qua-
perform the safety monitoring, case reports published in the sci-
litatively evaluated and studied for its ability of support real time
entific biomedical literature represent an important resource due
to their abundant existence, rapid rate of generation, and valuableinformation enclosed (Vandenbroucke, 2001). Due to their unstru-ctured nature, however, manual analysis of the scientific literature is
challenging, cumbersome, and labor intensive.
In recent years, development of automatic natural language pro-
cessing (NLP) and information extraction (IE) techniques have gai-
The data set used for training and validation of the relation extra-
ned immense popularity. They include identification of biomedical
ction system is the ADE corpus (Gurulingappa et al., 2012). The
named entities, relations between the entities, or events associa-
ADE corpus contains 2972 MEDLINE case reports that are manu-
ted with them. Noticeable efforts have been invested on mining the
ally annotated and harmonized by three annotators. The corpus
adverse effects in different forms of free-text data. Examples include
contains annotations of 5063 drugs, 5776 conditions (e.g. diseases,
Wang et al., 2009 who applied the MedLEE system on discharge
signs, symptoms), and 6821 relations between drugs and conditi-
summaries to identify medication events and entities that could be
ons representing clear adverse effect implications. All annotations
potential adverse entities that were detected using the strength of
are confined to sentence level i.e. drugs and conditions represen-
statistical association based on their co-occurrences. Leaman et al.,
ting adverse effects co-occurring only within individual sentences
2010 proposed a lenient NLP model for extracting adverse effects
are annotated. Drugs and conditions that do not fall into adverse
of drugs from social media such as blogs. Gurulingappa et al., 2011
effect relations are not annotated. This was done in accordance to
developed a machine learning-based system for classifying the sen-
tences in MEDLINE case reports that assert adverse effects of drugs.
The ADE corpus contains annotations of relations between drugs
However, according to the author’s knowledge, there is a limited
and conditions that represent True relations. This represents a spar-
focus on identification of semantic relationships between drugs and
sely annotated dataset. For training a supervised classifier, it was
adverse effects in text. This is partly due to the unavailability of sui-
essential to generate False relations i.e. drugs and conditions that do
table public corpora that could be used for technology development
not fall into adverse effect relations. For this purpose, ProMiner, a
and benchmarking. Extracting relations between drugs and adverse
dictionary-based named entity recognition system (Hanisch et al.,
effects can facilitate appropriate indexing, precise searching, visu-
2005) was employed. ProMiner was incorporated with DrugBank
alization, and faster information tracing. The use of ontology of
(Knox et al., 2011) and MedDRA (Merrill, 2008) dictionaries for theidentification of drugs and conditions respectively in the ADE corpus
∗Corresponding author: [email protected]; Gurulingappa and
that were previously not annotated by human annotators. As a result
of named entity recognition, new instances encompassing 2269
Gurulingappa et al
Table 1. Counts of entities and relations in ADE-EXT corpus subsets.
drugs and 3437 conditions were automatically annotated. Drug-condition pairs co-occurring within sentences that were previouslynot annotated by humans formed False relations. Altogether, 5968False relations were automatically generated. The corpus enrichedwith machine annotated drugs, conditions, and relations betweenthem is referred as ADE-EXT (indicating extended ADE corpus). Figure 1 shows an illustration of True and False relations between
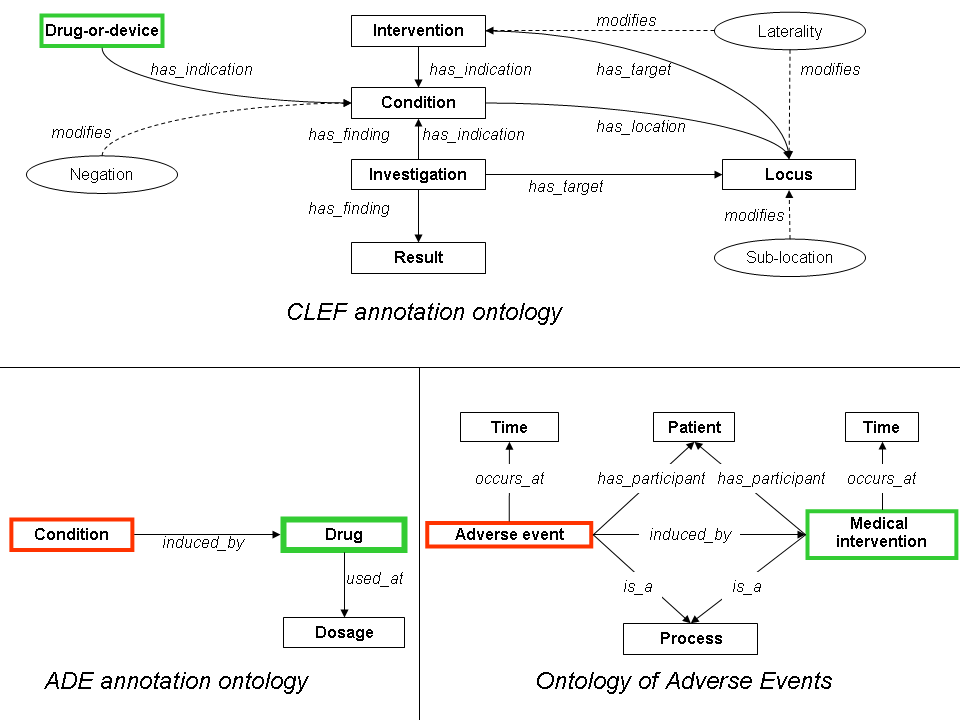
Fig. 2. Ontologies discussed in this work (from (Roberts et al., 2009) and
drug and conditions co-occurring within a sentence.
Mapping annotation ontology against Ontology ofAdverse Events
The CLEF initiative (Roberts et al., 2007) investigated how togenerate semantically annotated medical corpora for information
Fig. 1. Example of a sentence annotated with drug, conditions, and
extraction. As described (Gurulingappa et al., 2012) we adopted
relations between them. True indicates presence of adverse effect relation
the standard established by the CLEF framework for the annotation
and False indicates absence of adverse effect relation.
workflow (Roberts et al., 2009) however we reshaped the annota-tion schema by using only two of the original entities (CONDITION,
DRUG) and extended it with a third one (DOSAGE). None of the
In the ADE-EXT corpus, 120 manually annotated True relations
relationships used by the CLEF annotation schema could be reused
were not suitable for the NLP task. Examples include overlapping
for our work, since the CLEF annotation schema did not consider
inter-related entities such as acute lithium toxicity where lithium
adverse drug reactions, instead we created two relations: DRUG-
is related to acute toxicity. After removal of nested annotations,
CAUSE-CONDITION, DRUG-HAS-DOSAGE. In this work we focused
the ADE-EXT corpus was decomposed into a training set (ADE-
only on automating the detection of DRUG-CAUSE-CONDITION thus
EXT-TRAIN) and a test set (ADE-EXT-TEST). Counts of entities and
DOSAGE will not be mentioned further. The ADE corpus has been
relations in subsets of ADE-EXT corpora is shown in Table 1.
created using the Knowtator plugin for Prot´eg´e (Ogren, 2006), anontology-driven corpus annotation tool also used for the creation of
the CLEF corpus. Although we adopted the same tool used in CLEF
For the identification and extraction of drug-condition entity pairs
and also adopted the standard established by the CLEF framework
that fit into adverse effect relation, the Java Simple Relation Extra-
for the annotation workflow, we could not adopt the same annota-
ction (JSRE) system (Giuliano et al., 2007) was employed. JSRE
tion ontology since the latter was not able to capture the adverse
provides a re-trainable and scalable supervised classification plat-
drug relation and the drug dosing relation. The annotation onto-
form that uses Support Vector Machines (SVMs) (Burges, 1998)
logy described above was therefore used to create the ADE corpus.
with different kernels specially designed for the NLP and relation
Subsequent to the corpus creation, the realism-based biomedical
extraction. All sentences in ADE-EXT-TRAIN and ADE-EXT-TEST
ontology for representation of adverse events (AEO) has been publi-
containing drug-condition pairs labeled as either True or False were
shed (Yongqun et al., 2011). AEO has been developed following the
transformed into the SRE format before subjecting them to rela-
principles of Ontological Realism, thus is aligned with the Basic
tion extraction. The SRE format is a unique way of representing
Formal Ontology and the Relation Ontology, and with the Open
data within the JSRE platform where tokens appearing in sente-
Biological and Biomedical Ontologies (OBO) Foundry principles
nces are enriched with their parts-of-speech tags, lemmas, and flags
of openness, collaboration and use of a common shared syntax.
indicating if a token is a part of named entity or not. Amongst diffe-
AEO has 484 representational units, annotated by means of 369
rent kernels available, the shallow linguistic kernel was thoroughly
terms with specific identifiers and 115 terms imported from existing
used since it has been widely applied and has shown success during
ontologies. The use of ontologies has proven of great value in bio-
similar relation extraction tasks (Tikk et al., 2010). The ADE-EXT-
medicine, also since it enable machine reasoning, abstraction and
TRAIN was used as data for training and cross-evaluation of JSRE
automatic hypothesis generation. We therefore had interest in inve-
whereas the ADE-EXT-TEST was used an independent test set.
stigating if the knowledge encoded in the annotations of the ADE
Extraction of Adverse Drug Effects
Table 2. Assessment of results of relation
corpus could be semantically connected to the AEO. For doing this,
we manually compared the definitions of the entities of AEO and of
Table 3. Impact of the size of the training set.
ADE annotation ontology. Figure 2 shows the basic design patternsof AEO, ADE and CLEF as from the original papers, emphasizingshared entities using green and red colours.
Mapping the ADE Annotation Ontology to the
As clearly shown in Figure 2, both the ADE annotation ontology
The performance of relation extraction was evaluated by 10-fold
and the Ontology of Adverse Events represent adverse drug rea-
cross-validation of the training data. During cross-validation of the
ctions using formal ontological methods. Inspite of this common
training data and final evaluation over the test set, classification
goal, the two ontologies use different naming for the two core enti-
performances were assessed using the F-score over True-labeled
ties: a CONDITION in the ADE annotation ontology coincide with a
relations since they denote adverse effect relations between drugs
DRUG ADVERSE EVENT in AEO; a DRUG in the ADE annotation
and conditions that denote a focussed relation class being studied.
ontology coincide with a DRUG-ADMINISTRATION in AEO. The
ADE ontology additionally introduce the entity DOSAGE, not spe-
cified in AEO at the time of its development since AEO originallyfocused on vaccines for which dosing is not an essential medical
Baseline experiments began with training and cross-validation of
concept. Both ADE and AEO model a causal relationship between
JSRE over the ADE-EXT-TRAIN corpus. Results of system’s per-
CONDITION OR ADVERSE EVENT and DRUG OR MEDICAL INTE-
formances are shown in Table 2. The system achieved an overall
RVENTION , with the latter being the causal source. The only entity
F-score of 0.87 after cross-validation. Upon the final test over
shared by the CLEF annotation ontology with AEO and ADE is
ADE-EXT-TEST, the system attained F-score of 0.87 indicating a
the DRUG-OR-DEVICE, that coincide with a DRUG OR MEDICAL
consistency in classification. A subset of instances misclassified
during the cross-validation and testing were manually investiga-ted to understand the common sources of errors. Limited contextappeared to be one reason for misclassification. For example, the
CONCLUSION
title Niacin maculopathy (PMID:3174043) infers maculopathy as
This work reports on the adaptation of a machine learning-based
an adverse effect of niacin that lacks contextual description to
JSRE system for the identification and extraction of adverse effe-
support machine classification. Distantly co-occurring inter-related
cts of drugs in case reports. A methodology has been discussed to
entities constituted couple of errors. For example, in the sentence
enrich a sparsely annotated corpus and its subsequent use to build
CASE SUMMARY: A 65-year-old patient chronically treated with
a classification model. Evaluation of the system’s performance sho-
the selective serotonin reuptake inhibitor (SSRI) citalopram develo-
wed promising results. Performance of the system can be improved
ped confusion, agitation, tachycardia, tremors, myoclonic jerks and
in several ways. In the current experiments, only the default features
unsteady gait, consistent with serotonin syndrome, following initi-
acceptable by JSRE were used. Optimization of feature represen-
ation of fentanyl, and all symptoms and signs resolved following
tation to include additional features for instance from syntactic
discontinuation of fentanyl (PMID:17381671); the relation betw-
sentence parse trees may further improve the results. Development
een confusion and the last appearing drug name fentanyl was not
of additional strategies like post-processing to classify relations with
missing contextual descriptions can help to recover more relations.
The reported experimental results denote research status on
Impact of Size of the Training Set on the
adverse drug effect identification from text. There are several strate-
gies that will be immediately followed. The authors plan to bench-
In order to study the impact of size of the training data on per-
mark the performances of several named entity taggers against the
formance of classification, the ADE-EXT-TRAIN was decomposed
ADE corpus for the identification of drugs and conditions mentions
into random subsets containing 10, 20, 50, 100, 200, 500, 1000,
and 2000 documents. The JSRE was trained on these subsets
The current experiments have been performed on the ADE cor-
independently in different rounds and subsequently applied on the
pus, since that was the only one available when this work was done,
ADE-EXT-TEST for performance evaluation. Table 3 shows that alre-
however while writing this report a new corpus has been published,
ady using 500 documents one could achieve performances in the
namely the EU-ADR corpus(van Mulligen et al., 2012). It will be
80% range. Whereby, to reach a classifier with a standard deviation
interesting to see if the performance of JSRE on the ADE corpus will
of 1%, one needs a substantially large training data.
be different compared to the EU-ADR corpus. Gurulingappa et al
Similarly, benchmarking results of commercial and public rela-
extraction of drug-related adverse effects from medical case reports. Journal of
tion extraction systems such as SemRep, Luxid MER Skill
Hanisch, D., Fundel, K., Mevissen, H.-T., Zimmer, R., and Fluck, J. (2005). Prominer:
R , RelEx, MedScan will be performed. The outcome of
rule-based protein and gene entity recognition. BMC Bioinformatics, 6 Suppl 1,
relation extraction from text to support signal detection and identify
potentially novel or under-reported adverse effects will be studied.
Hauben, M. and Bate, A. (2009). Decision support methods for the detection of adverse
The use of ontologies for driving information extraction has been
events in post-marketing data. Drug Discov Today, 14(7-8), 343–357.
reported (Wimalasuriya and Dou, 2010; Pandit and Honavar, 2010),
Henegar, C., Bousquet, C., Lillo-Le Louet, A., Degoulet, P., and Jaulent, M.-C. (2006).
Building an ontology of adverse drug reactions for automated signal generation in
we plan to explore the use of various available tools (e.g. ODIE,
pharmacovigilance. Computers in Biology and Medicine, 36, 748–767.
semantixs) using the AEO ontology and compare the performance
Knox, C., Law, V., Jewison, T., Liu, P., Ly, S., Frolkis, A., Pon, A., Banco, K., Mak,
of the ontology driven methods against the method presented here.
C., Neveu, V., Djoumbou, Y., Eisner, R., Guo, A. C., and Wishart, D. S. (2011).
An outcome of the current work has demonstrated promising
Drugbank 3.0: a comprehensive resource for ’omics’ research on drugs. Nucleic
results and it has a potential to reduce the manual reading time, acce-
Acids Res, 39(Database issue), D1035–D1041.
Leaman, R., Wojtulewicz, L., Sullivan, R., Skariah, A., Yang, J., and Gonzalez, G.
lerate the signal tracking process, and therefore ensure safe use of
(2010). Towards internet-age pharmacovigilance: extracting adverse drug reacti-
ons from user posts to health-related social networks. In Proceedings of the 2010Workshop on Biomedical Natural Language Processing, pages 117–125.
Merrill, G. H. (2008). The meddra paradox. AMIA Annu Symp Proc, pages 470–474. ACKNOWLEDGEMENTS
Ogren, P. (2006). Knowtator: a Prot´eg´e plug-in for annotated corpus construction.
This work has been partly supported by Fraunhofer Institute for
In Proceedings of the 2006 conference of the North American chapter of the
Algorithms and Scientific Computing (SCAI), Sankt Augustin,
association for computational linguistics on human language technology, pages273–275.
Germany and Bonn-Aachen International Center for Information
Pandit, S. and Honavar, V. (2010). Ontology-guided extraction of complex nested relati-
onships. In 22nd IEEE International Conference on tools with artificial intelligence(ICTAI), pages 173–178.
Roberts, A., Gaizauskas, R., Hepple, M., Demetriou, G., Guo, Y., Roberts, I., and
REFERENCES
The CLEF corpus: semantic annotation of clinical text.
Aramaki, E., Miura, Y., Tonoike, M., Ohkuma, T., Masuichi, H., Waki, K., and Ohe, K.
Proceedings of the AMIA Symposium, pages 625–629.
(2010). Extraction of adverse drug effects from clinical records. In Studies Health
Roberts, A., Gaizauskas, R., Hepple, M., Demetriou, G., Guo, Y., Roberts, I., and
Technology Informatics, volume 160, pages 739–743.
Setzer, A. (2009). Building a semantically annotated corpus of clinical texts. Journal
Benton, A., Ungar, L., Hill, S., Hennessy, S., Mao, J., Chung, A., Leonard, C., and Hol-
of Biomedical Informatics, 42, 950–966.
mes, J. (2011). Identifying potential adverse effects using the web: A new approach
Tikk, D., Thomas, P., Palaga, P., Hakenberg, J., and Leser, U. (2010). A comprehensive
to medical hypothesis generation. Journal of Biomedical Informatics, 44, 989–996.
benchmark of kernel methods to extract protein-protein interactions from literature.
Burges, C. (1998). A Tutorial on Support Vector Machines for Pattern Recognition.
Data Mining and Knowledge Discovery, 2.
van Mulligen, E., Fourrier-Reglat, A., Gurwitz, D., Molokhia, M., Nieto, A., Trifiro,
Delamarre, D., Lillo-Le Louet, A., Jamte, A., Sadou, E., Ouazine, T., Burgun, A.,
G., Kors, J., and Furlong, L. (2012). The eu-adr corpus: Annotated drugs, diseases,
and Jaulent, M. (2010). Documentation in pharmacovigilance: using an ontology to
targets, and their relationships. Journal of Biomedical Informatics.
extend and normalize Pubmed queries. In Studies Health Technology Informatics,
Vandenbroucke, J. P. (2001). In defense of case reports and case series. Ann Intern
Giuliano, C., Lavelli, A., Pighin, D., and Romano, L. (2007). FBK-IRST: Kernel Meth-
Wang, X., Hripcsak, G., Markatou, M., and Friedman, C. (2009). Active computeri-
ods for Semantic Relation Extraction. In Proceedings of the Fourth International
zed pharmacovigilance using natural language processing, statistics, and electronic
health records: a feasibility study. J Am Med Inform Assoc, 16(3), 328–337.
Gurulingappa, H., Fluck, J., Hofmann-Apitius, M., and Toldo, L. (2011).
Wimalasuriya, D. and Dou, D. (2010). Ontology-based information extraction: an intro-
tification of adverse drug event assertive sentences in medical case reports.
duction and a survey of current approaches. Journal of Information Science, 36,
First International Workshop on Knowledge Discovery and Health Care Manage-
ment (KD-HCM), European Conference on Machine Learning and Principles and
Yongqun, H., Zuoshuang, X., Sarntivijai, S., Toldo, L., and Ceusters, W. (2011). AEO:
Practice of Knowledge Discovery in Databases (ECML PKDD).
A Realism-Based Biomedical Ontology for the Representation of Adverse Events.
Gurulingappa, H., Mateen-Rajput, A., Roberts, A., Fluck, J., Hofmann-Apitius, M.,
In ICBO: International on Biomedical Ontology Buffalo, NY, USA, Representing
and Toldo, L. (2012). Development of a benchmark corpus to support the automatic
Mitteilungen der NGM -2.Jahrgang Heft 2 Juni 2002 – Der Alte Friedhof in Parchim als Refugium verwilderter Liliengewächse Seiten 109Der Alte Friedhof in Parchim als Refugium verwilderter Seit die verwilderten Liliengewächse in Mecklenburg-Vorpommern intensiv kartiert werden, ist der Alte Friedhof in Parchim verstärkt ins Blickfeld der Botaniker gerückt. In seinen Rasenflächen haben sich
Ethical issues arising from the use of assisted reproductive technologies Introduction warrant attention, balance and prioritization. Balanceand prioritization may be achieved in different ways,The purpose of this paper is to address ethical issuesdepending upon the ethical orientations, principlesarising from four aspects of the employment ofand levels of analysis that are brought to be

 Gurulingappa et al
Gurulingappa et al